Robotics - Utility and Influence Diagrams¶
Background¶
Robotics are becoming common place in many business situations. For example in retail sales robotics are used in warehouse management. Amazon is widely known to be a leader in this area. But, according to a recent Wall Street Journal article, UK online grocery retailer, Ocado, is rumored to have even more sophisticated order fulfilment robotics.
https://www.wsj.com/articles/how-robots-and-drones-will-change-retail-forever-1539604800
Not surprisingly, companies like Amazon and Ocado do not disclose much information on their robotics. Nonetheless, we can be sure that sensor fusion is a significant problem. For example, sensor fusion is a significant issue with self driving cars. See for example:
https://arxiv.org/ftp/arxiv/papers/0709/0709.1099.pdf
Bob's Orchards is a premium seller of apples and pears. Bob's customers pay a substantial premium for superior fruit. To satisfy these customers, Bob's must ensure that the fruit delivered is correctly packed and perfectly ripe.
Like many legacy industries requiring specialized human skills, Bob's is facing a talent problem. Many of the human inspectors who expertly check each piece of fruit shipped for ripeness are approaching retirement age. Management's attempts to recruit younger people to apprentice as fruit inspectors have been, well, fruitless (oh, sorry!:). Therefore, it has become imperative to find some type of automated system which can reduce the workload on the diminishing number of human inspectors. To address this problem, Bob's is deploying technology from Robots R Us.
Scenario : Robot Inspector¶
The first robotic system to be deployed at Bob's uses a multi-sensor array to determine if the fruit being shipped is at the correct ripeness. There are two sensors, a vision system that examines the fruit for spots, indicating the fruit is over ripe, and a smell sensor that determines if the fruit is not ripe enough. If either sensor indicates the fruit is bad it is sent to a human inspector. In addition customers may reject even perfect fruit for no apparent reason, whereas others seem perfectly happy with less than perfect fruit.
The probability distributions, decisions and utilities of this system can be summarized as follows:
- The unconditional probability distribution of the ripeness of the fruit being packed is known
- The probability that each sensor reads correctly or not is known experimentally. A table must be constructed that gives computes the conditional probability of accepting or rejecting fruit given the actual ripeness. More on this latter.
- The decision is then made to have a human inspector examine the fruit or not.
- The utility of the human inspection of the fruit.
- The conditional probability of a customer accepting or not good depending on if the order is good or bad.
- The utility of the customer accepting or rejecting an order.
Steps¶
Perform this analysis with following steps:
- Draw an influence diagram for the fruit inspection task.
- Use Python, with numpy and optionally Pandas, compute and compare the utility for using robot aided inspection.
- Compare the utility of robot aided inspection to the current manual inspection process.
Introduce the basis¶
Basics of Utility Theory¶
To make optimal decisions an intelligent agent must have a way to measure the value of the outcomes. Creating functions to measure the value of outcomes is the domain of utility theory.
Let's think about a simple example. Let's say that you go to a charity dinner and you buy a raffle ticket to win a prize worth \$1,000. There are 100 tickets and each ticket costs $100. Your joy of supporting this important charity is worth 200 to you. What is your utility of buying one ticket:
$$U(1) = -p(buy) * cost + p(feeling) * value + p(win) * 1000 \\ = - 1.0 * 100 + 1.0 * 200 + 0.01 * 1000 \\ = 110$$
From the foregoing example you can likely see that the general form of a utility function can be expressed:
$$U(S) = \sum_{s} p(s)\ u(s)\\ where\\ p(s) = probability\ of\ state\ s\\ u(s) = utility\ of\ state\ s $$
Let's continue with the example. There is no reason that a utility function should have linear scaling. To understand this consider what your utility will be if you buy two raffle tickets. Your cost is now $200 for the tickets, and you have doubled your chance of winning the prize. You might think that your utility might be only 20. But, perhaps not. Your joy at helping the charity might be 400 making your utility of your larger donation:
$$U(2) = - 1.0 * 2 * 100 + 1.0 * 400 + 0.01 * 2 * 1000 \\ = 220$$
From the above, you can see that amount of money does not equal utility. To understand this concept consider the following situation. In his youth, your instructor took many long backpacking trips. The person who organized the food for one 5-day hike did a poor job. Meals were minimal, and by the last day, there was no food left at all. We arrived in Aspen Colorado in mid afternoon quite hungry. We found a popular hamburger restaurant and spent the very last bit of money to buy a hamburger. The utility of that hamburger was much greater than the price paid. Then as now, Aspen is a playground of the wealthy. It is very likely that the utility of a hamburger to these wealthy customers was considerably less than too a young man who has not had enough to eat for several days!
Actions and Expected Utility¶
By itself, a utility function does not tell us anything about the results of actions the agent might take. The expected utility function is the product of the value of a state multiplied by the probability of being in a state given the observation and the action:
$$E \big[ U(a\ |\ o) \big] = \sum_{s'} p(s'\ |\ a,o)\ U(s') $$
For a planning problem we want to find the optimal action, $a$, such that:
$$argmax_a E \big[ U(a\ |\ o) \big] = argmax_a \sum_{s'} p(s'\ |\ a,o)\ U(s') $$
While simple conceptually, directly applying the above formulation to solve for the optimal action can be difficult beyond the simplest problems. An example of such a problem can be represented as a decision tree, which allows relatively direct solution.
Influence Diagram¶
This is the use of Bayesian networks as a representation of probability distribtuions and their independecies.
A representation for a decision process must preserve causality. A decision cannot be made until previous decisions have been made and resulting state is observed. Bayesian networks represent causality or influence of one set of variables to others.
There are two additional elements that must be added to Bayesian networks to transform them to influence diagrams:
- Decision nodes which have no distribution. In effect, the decision nodes are like switches which initiate actions in the environment. We illustrate decisions nodes as rectangles.
- Utility nodes, which measures the value of the states of the environment. We illustrate utility nodes as diamonds.
We also need three types of directed edges to specify influence diagrams.
- Edges that propagate belief, or conditional information as we used before.
- Informational edges which propagate information that is not related to a distribution or belief.
- Functional edges which end in utility nodes which propagate the information needed for the utility calculation.
Let's look at a few simple cases that occur in influence diagrams. As illustrated in the diagram below a random variable in an influence diagram can be dependent on both other random variables as well as decisions. We have already spent considerable time on dependencies and independencies of random variables. But consider what happens when a decision is imposed. The decision will force the probabilities of some states to 0. That is, a decision allows some states but not others to occur.
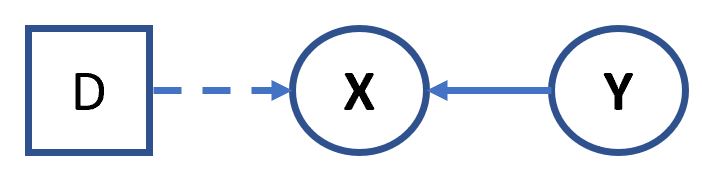
In the above diagram notice that the edge between the decision and the random variable is shown as an information link. This is because, decisions have no distributions associated with them.
The diagram below shows how a utility node can be dependent on both random variables and decision nodes. We have already discussed how a probability distribution is used to compute utility. A decision will fix the set of states which are possible and therefore the total utility.
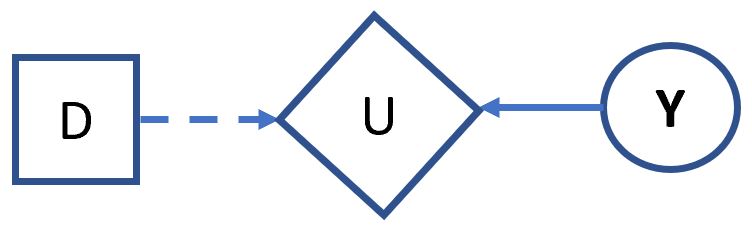
In the above case, the diagram contains two function edges, one with distribution information and the other with decision information.
Consistency and Partial Ordering¶
As has already been mentioned causality is important in influence diagrams. This property is know as causal consistency. Influence in must be in causal order. This organization is called partial ordering.
Let's say that we have a series of variables, $\chi_i$, separated by decision variables, $D_i$. The variable $\chi_i$ must be observed before the decision $D_i$ can be made. The variable $\chi_{i+1}$ cannot be observed before decision $D_i$ is made. We represent the partial ordering with the precedence symbol, $\prec$. We represent this situation as:
$$\chi_1 \prec D_1 \prec \chi_2 \prec D_2 \ldots \chi_n \prec D_n$$
Inference on Influence Diagrams¶
In previous lessons, we explored a number of widely used exact inference methods for Bayesian belief networks. It turns out that many of the inference methods for Bayesian networks, like variable elimination, belief propagation, and the junction tree algorithm, can be applied to the case of influence diagrams as well.
Here, we will only touch on the variable elimination method. Variable elimination for influence diagrams follows a similar process as for Bayesian networks. The difference being that we proceed in the reverse of the partial ordering.
Given the partial ordering of a set of random variables $x_t$ and decision variables $d_t$ we can write the probability of the $T$th state:
$$p(x_{1:T}, d_{1:T}) = \prod_{t = 1}^T p(x_t\ |\ x_{t-1}, d_{1:t})$$
Multiplying through by the utility, $u(x_{1:T}, d_{1:T})$ we can maximize the sums over the variables for each of the decisions:
$$max_{d_1} \sum_{x_1} \cdots max_{d_{T}} \sum_{x_{T}} \prod_{t = 1}^T p(x_t\ |\ x_{t-1}, d_{1:t})\ u(x_{1:T}, d_{1:T})$$
We can rearrange the sums so that we can eliminate variables, resulting in a new marginal utility variable, $\widetilde{u}(x_{1:T-1}, d_{1:T-1})$:
$$ max_{d_1} \sum_{x_1} \cdots max_{d_{T-1}} \sum_{x_{T-1}} \prod_{t = 1}^{T-1} p(x_t\ |\ x_{t-1}, d_{1:t})\ max_{d_{T}} \sum_{x_{T}} p(x_T\ |\ x_{1:T-1}, d_{1:T}) u(x_{1:T}, d_{1:T}) \\ = max_{d_1} \sum_{x_1} \cdots max_{d_{T-1}} \sum_{x_{T-1}} \prod_{t = 1}^{T-1} p(x_t\ |\ x_{t-1}, d_{1:t})\ \widetilde{u}(x_{1:T-1}, d_{1:T-1})$$
There is one factorization we can apply to variable elimination on influence diagrams to simplify the problem. We can take advantage of the fact that early decisions are independent of latter decisions since the later decisions are not yet known. Thus, in many cases we can simply sum the marginal utilities.
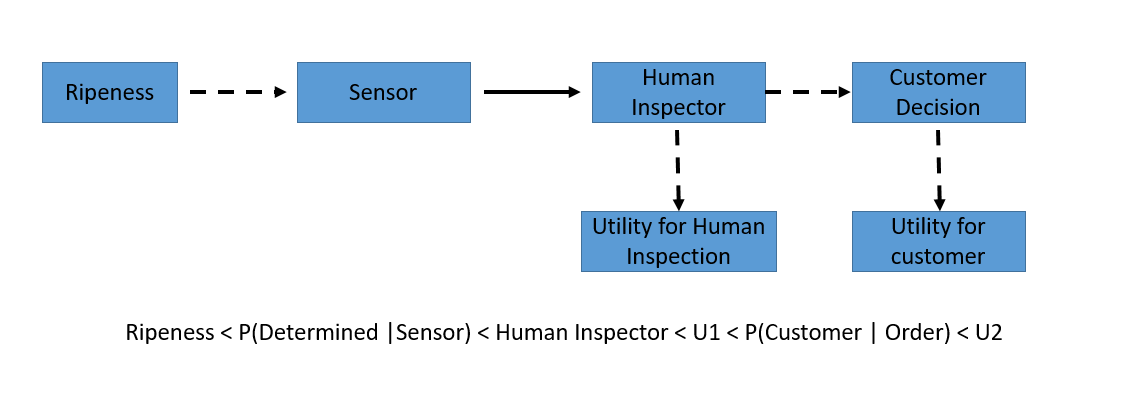
$$Ripeness \prec P(Determined\ | \ Sensor) \prec Human \ Inspector \prec U1 \prec p(Customer\ |\ order) \prec U2$$
import numpy as np
import pandas as pd
we will now perform variable elimination on our influence diagram. we start with the conditional probability of the customer being satisfied and the order and the utility of order delivery.
The conditional probability of the customer being satisfied is shown here:
| good order | bad order | |
|---|---|---|
| satisfied | 0.95 | 0.10 |
| not satisfied | 0.05 | 0.90 |
And the utility of the satisfied and unsatisfied customers is:
| Satisfied | Not Satisfied | |
|---|---|---|
| Utility | 20 | -40 |
Now, given these tables, compute the marginal utility for customers with good and bad orders.
customer = np.array([[0.95, 0.10],[0.05,0.90]])
U1=([20,-40])
customer_utility = np.transpose(np.multiply(np.transpose(customer), U1))
print(customer_utility)
margin_customer_utility = np.sum(customer_utility,axis = 0)
margin_customer_utility
With the first set of variables eliminated, we will deal with eliminating the second set of variables, our goal is to find the marginal distribution of good and bad orders given the inspection, or not, of packages for suspected bad orders. Keep in mind that some bad orders will not be correctly detected.
Most unfortunately for Bob's, Robots R U engineers have little experience with fruit processing and the sensors are known to be unreliable. The probability of a correct reading from the spot sensor is 0.9 and for the smell sensor the probability of a correct reading is 0.7. If ether sensor indicates the fruit is not ripe, we consider the fruit as bad. This leads to 4 possible result states when integrating data from these sensors:
- The fruit is actually good, a true positive
- Good fruit is considered bad, a false negative.
- The fruit is actually bad, a true negative.
- Bad fruit is considered good, a false positive.
Since we demand agreement from both sensors that the fruit is good we must construct a table based on the following logic. This leads to the following interpretation of the sensor tuples (spots, smell);
- Both sensors indicate good (G,G), in which case the fruit is assumed good.
- Either or both sensors indicate the fruit is bad (G,B, B,G, BB) in which case the fruit is assumed bad.
The tuple of states of the spot and smell sensors can be any of the following 4, where T = true reading, F = false reading:
- The spot and smell sensors can both read correctly;(T,T),
- The spot sensor reads correctly, but the smell sensor reads in error; (T,F),
- The spot sensor reads in error, and the smell sensor reads correctly; (F,T),
- Both the spot and smell sensors read in error; (F,F).
Now, the two sensors work independently, and measure quite different physical properties of the fruit, so it is a good assumption the probability of true and false readings for the two senors are statistically independent. Given this logic, the probabilities for the CPD table are computed using the probabilities of true and false readings of the spot and smell sensors, (p(spot), p(smell)), as follows:
| Classification | G,G | G,B | B, G | B,B |
|---|---|---|---|---|
| Good | p(T) * p(T) | 0.0 | 0.0 | 0.0 |
| Good as Bad | 0.0 | p(T) * p(F) | p(F) * p(T) | p(F) * p(F) |
| Bad | 0.0 | p(T)p(T) + p(F)p(T) + p(F) * p(T) | p(T) p(T) + p(T) p(F) + p(F) * p(T) | p(T) p(T) + p(F) p(T) + p(T) *p(F) |
| Bad as Good | p(F) p(F) + p(T) p(F) + p(F) * p(T) | 0.0 | 0.0 | 0.0 |
As given the focus on quality, Bob's has developed a process to ensure fruit entering the shipping stage of its process is ripe. However, given the practical issues around picking fruit in a real world orchard, the probability that fruit at this stage of the process is ripe is 0.8. There are several ways to represent this information in your model. Perhaps the simplest way is:
| Good | Good as Bad | Bad | Bad as Good | |
|---|---|---|---|---|
| Probability | 0.8 | 0.8 | 0.2 | 0.2 |
Given these tables, compute the marginal distribution of correct and incorrect orders, Good, Good as Bad, Bad and Bad as Good.
given_probability = np.array([0.8,0.8,0.2,0.2])
Spot = 0.9
Smell = 0.7
CPD = np.array([[Spot*Smell,0,0,0],
[0,Spot*(1-Smell),(1-Spot)*Smell,(1-Spot)*(1-Smell)],
[0,Spot*Smell+(1-Spot)*Smell+(1-Spot)*(1-Smell), Spot*Smell + Spot*(1-Smell)+
(1-Spot)*(1-Smell), Spot*Smell+(1-Spot)*Smell+Spot*(1-Smell)],
[(1-Spot)*(1-Smell)+Spot*(1-Smell)+(1-Spot)*(Smell),0,0,0]])
#Spot*Smell+Spot*(1-Smell)+(1-Spot)*Smell+(1-Spot)*(1-Smell)
ripe_CPD = np.transpose(np.multiply(np.transpose(CPD),given_probability))
print(CPD)
print(ripe_CPD)
ripe_margin = np.sum(ripe_CPD,axis=0)/np.sum(ripe_CPD) #marginal
print(ripe_margin)
Question: Given the unreliability of the sensors, is more bad fruit classified as bad or more good fruit classified as bad?
ANS: Good fruit classified as bad is more likely than bad as bad.
For the next step of this analysis you must compute the marginal utility of inspecting suspected bad fruit (Good, Good as Bad, Bad, Bad as G). The utility of such an inspection is -10. Again, there are several ways to represent the utility of inspection in your model. One possibility is:
| Good | Good as Bad | Bad | Bad as Good | |
|---|---|---|---|---|
| Utility | 0.0 | 10.0 | 10.0 | 0.0 |
U2 = np.array([0,-10,-10,0])
inspect_utility = np.multiply(np.transpose(ripe_CPD),U2)
print(inspect_utility)
marginal_inspect_utility = np.sum(inspect_utility, axis =0)
print(marginal_inspect_utility)
Bob's human fruit inspectors are extremely dedicated and experienced. In the following we can safely assume that the probability of good fruit following the inspection is 1.0.
There are two possibilities for the decision node, inspect the suspect fruit, or ship the order as is. To find out we will need to compute the total utility for both cases. In both cases, the steps are:
- Compute the probabilities of delivering good or bad fruit.
- Compute the total utility, using the marginal utility for delivery and the marginal utility for inspection (or not) we have already computed.
First, compute the total utility of not inspecting suspect fruit.
good_fruit = np.array([0.8,0.2])
np.sum(np.multiply(good_fruit,margin_customer_utility))
Now compute the total utility if all suspect fruit is inspected.
good_bad3 = np.array([np.sum(ripe_margin[[0]]),ripe_margin[3]])
print(good_bad3/np.sum(good_bad3))
print(np.multiply(good_bad3/np.sum(good_bad3),margin_customer_utility))
print(np.sum(np.multiply(good_bad3/np.sum(good_bad3),margin_customer_utility))++np.sum(marginal_inspect_utility))
#sensor only
good_bad2 = np.array([np.sum(ripe_margin[[0,1]]),ripe_margin[3]])
print(good_bad2/np.sum(good_bad2))
print(np.multiply(good_bad2/np.sum(good_bad2),margin_customer_utility))
print(np.sum(np.multiply(good_bad2/np.sum(good_bad2),margin_customer_utility)) +np.sum(marginal_inspect_utility))
#utility for food inspection without bad as bad things (we will throw out)
Question: Given the reliability of the sensors and the quality of the incoming fruit, is it better to inspect the fruit?
ANS: No, the utility is lower than 0 (doing nothing) when we do inspect the fruit.
As already indicated, the current process is to have humans inspect all shipments at a utility of -10. Keeping in mind that even customers who receive perfect fruit are not always satisfied, compute the utility of the current process.
margin_customer_utility[0]-10 #human only
sensor and human both¶
np.sum(np.multiply(good_bad2/np.sum(good_bad2),margin_customer_utility)) +np.sum(marginal_inspect_utility)
#total utility
Conclusion Question:¶
Is the maximum total utility of the process with the robotic inspection better than the human only process?
No, it is better to do the human only process if we do inspection without bad as bad fruit.
To recapitualte, our robotic system for inspecting whether the fruits are good has to be changed, or just removed!